

Hadoop认证教程:HDFS的数据复制
Hadoop认证教程:HDFS的数据复制,HDFS被设计成在一个大集群中可以跨机器可靠地存储海量的文件。它将每个文件存储成Block序列,除了最后一个Block,所有的Block都是同样的大小。文件的所有Block为了容错都会被冗余复制存储。每个文件的Block大小和Replication因子都是可配置的。
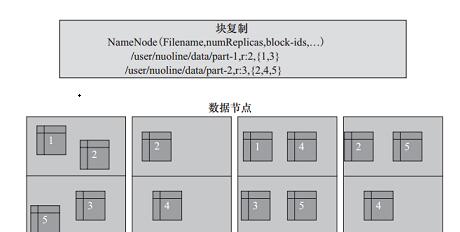
Replication因子在文件创建的时候会默认读取客户端的HDFS配置,然后创建,以后也可以改变。HDFS中的文件是write-one,并且严格要求在任何时候只有一个writer。HDFS数据冗余复制示意图如3-6图所示。
从图3-6中可以看到,文件/user/nuoline/data/part-1的复制因子Replication值是2,块的ID列表包括1和3,可以看到块1和块3分别被冗余备份了两份数据块;文件/user/nuoline/data/part-2的复制因子Replication值是3,块的ID列表包括2、4、5,可以看到块2、4、5分别被冗余复制了三份。在HDFS中,文件所有块的复制会全权由NameNode进行管理,NameNode周期性地从集群中的每个DataNode接收心跳包和一个Blockreport。心跳包的接收表示该DataNode节点正常工作,而Blockreport包括了该DataNode上所有的Block组成的列表。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

