

Hadoop大数据教程:基于Streaming实现作业提交
Hadoop大数据教程:基于Streaming实现作业提交,通过执行2.4.2中Streaming方式的编译命令后,会得到可执行程序WordcountMap和WordcountReduce,分别为词频统计的Map和Reduce,然后就可以使用Hadoop Streaming命令来实现作业提交。提交运行脚本的命令如下:
#!/bin/bash
#提交运行脚本
HADOOP_VERSION=1.0.4
Work_path=/home/nuoline/swordcount #用户程序所在目录
HADOOP_HOME=/home/nuoline/Hadoop-$HADOOP_VERSION
streaming=$HADOOP_HOME/contrib/streaming/Hadoop-streaming-$HADOOP_VERSION.jar
$HADOOP_HOME/bin/Hadoop jar $streaming \
-f?ile $Work_path/WordcountMap \
-mapper WordcountMap \
-f?ile $Work_path/WordcountReduce \
-reducer WordcountReduce \
-input /usr/nuoline/wordcount/sinput \
-output /usr/nuoline/wordcount/soutput \
-numReduceTasks 1 \
-jobconf MapRed.job.name="MyWordcount"
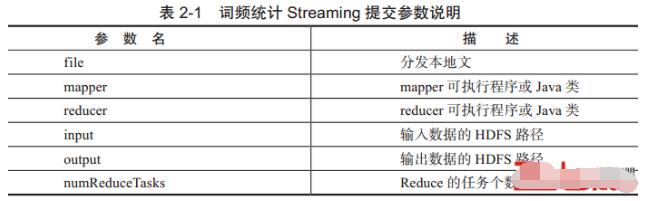
在上述提交运行脚本的命令中需要指定HADOOP_HOME环境变量。Streaming命令中最基本的参数说明如表2-1所示。
Streaming用户非常灵活,用户在提交作业到Hadoop集群之前最好能在本地测试一下。本地测试可以使用Linux命令来模拟Hadoop处理流程,命令如下:
cat input.txt / WordcountMap / sort / WordcountReduce > output.txt
input.txt是词频统计的测试用例,output.txt是输出,需要注意的是Map之后需要sort命令,这是因为在Hadoop中Map处理完之后会依据键key进行排序,如果程序在本地测试正常,就可以安全地将其提交到Hadoop上运行。Streaming本身还有很多用法,更详细的内容将在后续章节进行详细介绍。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

