

Hadoop基础课程:Java API怎么实现
Hadoop基础课程:Java API怎么实现,对Java程序员来讲,直接调用Hadoop的Java API来实现是最为方便的,要使用Java API至少需要实现三个重要组件:Map类、Reduce类、驱动Driver。下面将具体实现Java API的词频统计程序。
(1)实现Map类:WordcountMapper.java,核心代码如下:
import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.Hadoop.MapReduce.Mapper;public class WordcountMapper extends Mapper<object, intwritable="">{ private f?inal static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }</object,>首先要实现Map需要继承Hadoop的Mapper类,至少需要实现其中的map方法,其中Mapper中的map方法通过指定的输入文件格式一次处理一行,value就是map函数接收到的输入行,然后通过StringTokenizer以空格为分隔符将一行切分为若干tokens,之后,输出形式的键值对并将它写入org.apache.hadoop.mapred.OutputCollector中。为了更加清晰地认识Map阶段的处理,我们假设有三个文本a、b、c,使用上述实现的处理流程如图2-5所示。
从图中可以看到对于文件A的输入,相应的Map处理之后还会进行sort,最终Map输出如下:
<Hello,1><nuoline,1><nuoline,1><Welcome,1>对于文件B,执行相应的sort之后最终Map输出如下:
<hadoop,1><hadoop,1><Hello,1><Welcome,1>对于文件C,执行相应的sort之后最终Map输出如下:
<cloud,1><cloud,1><Hello,1><Welcome,1><welcome,1></welcome,1>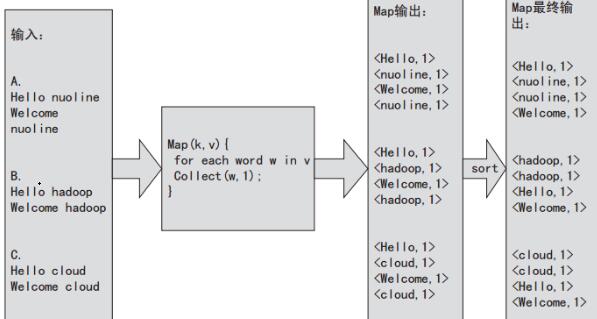
(2)实现Reduce类:WordcountReducer.java,核心代码如下:
import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;public class WordcountReducer extends Reducer<text,intwritable,text,intwritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<intwritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }</intwritable></text,intwritable,text,intwritable>实现WordcountReducer类需要继承Reducer,至少需要实现其中的reduce方法,输入参数中的key和values是由Map任务输出的中间结果,values是一个Iterator,遍历这个Iterator就可以得到属于同一个key的所有value。此处key是一个单词,values是词频。只需要将所有的values相加,就可以得到这个单词总的出现次数。
对于图2-5的Map输出,Reduce处理的示意图如图2-6所示。
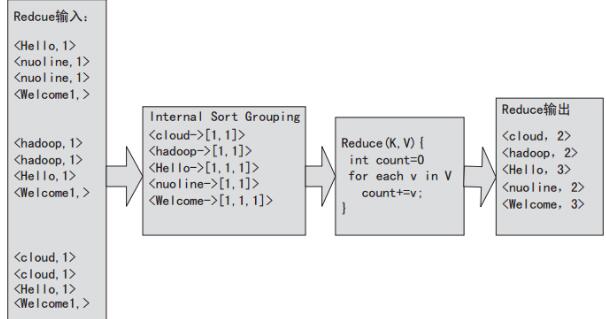
从图中可以看出,Reduce的输入就是Map的输出,然后会进行sort group,将Reduce的输入变为>的形式,接着Hadoop框架会使用用户指定的Reduce类处理数据,并最终输出。当然用户还可以指定combiner,每次Map运行之后,会按照key对输出进行排序,然后把输出传递给本地的combiner(可以指定和Reducer一样),进行本地聚合。运行combiner能减少数据的通信量并降低Reduce的负载。
(3)实现运行驱动
运行驱动的目的就是在程序中指定用户的Map类和Reduce类,并配置提交给Hadoop时的相关参数。例如实现一个词频统计的wordcount驱动类:MyWordCount.java,其核心代码如下:
import org.apache.hadoop.conf.Conf?iguration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class MyWordCount { public static void main(String[] args) throws Exception { Conf?iguration conf = new Conf?iguration(); Job job = new Job(conf, "word count"); job.setJarByClass(MyWordCount.class); job.setMapperClass(WordcountMapper.class); job.setCombinerClass(WordcountReducer.class); job.setReducerClass(WordcountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }}从上述核心代码中可以看出,需要在main函数中设置输入/输出路径的参数,同时为了提交作业,需要job对象,并在job对象中指定作业名称、Map类、Reduce类,以及键值的类型等参数。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

