

Hadoop基础教程:MapReduce模型
Hadoop基础教程:MapReduce模型,在并行计算领域最著名的就是MPI模型,MPI是一种消息传递编程模型,在大规模科学计算领域已经成功应用了数年,而MapReduce则是一种近几年出现的相对较新的并行编程技术,但是MapReduce计算模型也是建立在数学和计算机科学基础上的,实践已经证明这种并行编程模型具有简单、高效的特点,最为重要的两个概念就是Map和Reduce,最基本的处理思想就是“分而治之,然后归约”。
Hadoop会将一个大任务分解为可以同时执行的多个小任务,从而达到并行计算的目的。举个简单的例子,对于一个大型任务,单机处理需要1024分钟,而分解为1024个子任务并行执行就可在1分钟完成处理。在对处理的数据集的要求上,相比于传统关系数据库的结构化数据,MapReduce模型的Hadoop框架适合半结构化或非结构化的数据。
Hadoop通过自动分割将要执行的问题(程序)、拆解成Map(映射)和Reduce(化简)的方式,其分解过程的实质是将问题分为几个部分,划分为可以应用于程序的数据,再将数据分解,然后对分解的数据进行并行操作,在自动分割后通过Map程序将数据映射成不相关的区块,分配(调度)给大量的计算机进行处理以达到分散运算的效果,再通过Reduce程序将结果汇总整合,输出开发者需要的结果。
Hadoop向用户提供了一个规范化的MapReduce编程接口,用户只需要编写Map和Reduce函数,这两个函数都是运行在键-值对基础上的,数据的切分,节点之间的通信协调等全部由Hadoop框架本身来负责。一般一个用户作业提交到Hadoop集群后会根据输入数据的大小并行启动多个Map进程及多个Reduce进程(也可以是0个或者1个)来执行。MapReduce也具有弹性适应性,小数据和大数据仅仅通过调整节点就可以处理,而不需要用户修改程序。MapReduce模型处理流程,如图1-4所示。
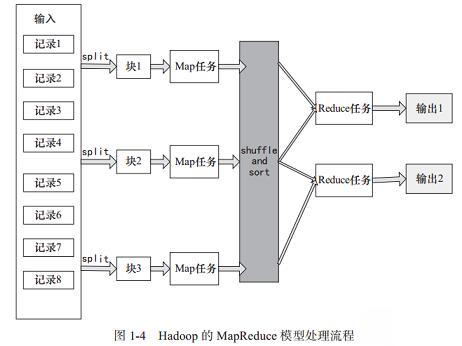
上图就是MapReduce的数据处理流程图,在Map之前会对输入的数据有split的过程,默认split就是写入数据时的逻辑块,每一个块对应一个split,一个split就对应一个Map进程,正是split保证了任务的并行效率。在Map之后还会有shuffle和sort的过程,shuffle简单描述就是一个Map的输出应该映射到哪个Reduce作为输入,sort就是指在Map运行完输出后会根据输出的键进行排序。这两个处理步骤对于提高Reduce的效率及减小数据传输的压力有很大的帮助。
从本质上讲MapReduce借鉴了函数式程序设计语言的设计思想,其软件实现是指定一个Map函数,把键值对(key/value)映射成新的键值对(key/value),形成一系列中间结果形式的键值对(key/value),然后把它们传给Reduce(归约)函数,把具有相同中间形式key的value合并在一起。Map和Reduce函数具有一定的关联性。其算法描述为:
Map(k,v)-> list(k1,v1)
Reduce(k1,list(v1))->list(v1)
在Map过程中将数据并行,即把数据用映射函数规则分开,而Reduce则把分开的数据用归约函数规则合在一起,即Map是个分的过程,Reduce则对应着合。后面章节将会具体讲述这部分的具体内容。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

