

Hadoop基础教程:HDFS数据存储与切分
Hadoop基础教程:HDFS数据存储与切分,在Hadoop中数据的存储是由HDFS负责的,HDFS是Hadoop分布式计算的存储基石,Hadoop的分布式文件系统和其他分布式文件系统有很多类似的特质。简单总结有如下的基本特征:
对于整个集群有单一的命名空间。
数据一致性。适合一次写入多次读取的模型,客户端在文件没有被成功创建之前无法看到文件存在。
文件会被分割成多个文件块,每个文件块被分配存储到数据节点上,而且根据配置会有复制文件块来保证数据的安全性。
在Hadoop中数据存储涉及HDFS的三个重要角色,分别为:名称节点(NameNode)、数据节点(DataNode)、客户端。
NameNode可以看做是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息、存储块的复制。NameNode会存储文件系统的Metadata在内存中,这些信息主要包括文件信息,即每一个文件对应的文件块的信息,以及每一个文件块在DataNode的信息。
DataNode是文件存储的基本单元。它将Block存储在本地文件系统中,保存了Block的Metadata,同时周期性地发送所有存在的Block的报告给NameNode。Client就是需要获取分布式文件系统文件的应用程序。数据存储中的读取和写入过程,如图1-3所示。
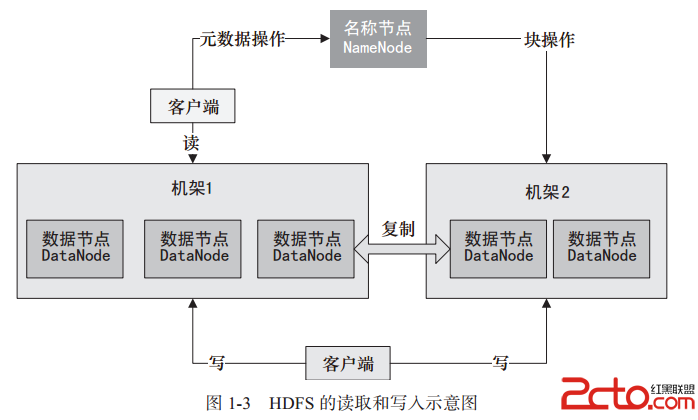
从图1-3中可以看到,数据存储过程中主要通过三个操作来说明NameNode、DataNode、Client之间的交互关系。根据图1-3所示的内容我们简单分析一下Hadoop存储中数据写入和读取访问的基本流程步骤。
文件写入HDFS的基本流程如下:
1)Client向NameNode发起文件写入的请求。
2)NameNode根据文件大小和文件块配置情况,向Client返回它所管理的DataNode的信息。
3)Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入每一个DataNode中。
文件读取HDFS的基本流程如下:
1)Client向NameNode发起文件读取的请求。
2)NameNode返回文件存储的DataNode的信息。
3)Client读取文件信息。
在HDFS中复制文件块的基本流程如下:
1)NameNode发现部分文件的Block不符合最小复制数或部分DataNode失效。
2)通知DataNode相互复制Block。
3)DataNode开始相互复制。
通过上面三个流程我们基本了解了Hadoop是如何使用HDFS存储数据的,那么在Hadoop中数据是如何切分的呢?我们知道HDFS在具体存储文件数据时先划分为逻辑Block块,后续的写入、读取、复制都是以Block块为单元进行的。那么在Hadoop中数据处理时存储在HDFS上的数据是如何切分呢?其实从HDFS的文件写入过程就可以看出,在Client和NameNode交互的同时是需要加载客户端的Hadoop配置文件的,如果用户设置了块的大小配置属性dfs.block.size,就会按照用户自定义的大小进行逻辑切分,如果没有配置,则使用集群默认的配置大小,因此在写入数据时文件已经在逻辑上切分好了,在运行MapReduce时默认就会按照切分好的块大小和数量来启动Map,也就是默认Map的数量是在数据写入时就确定好的,当然用户也可以指定文件数据的切分大小,可通过mapred.min.split.size参数在将作业提交客户端时进行自定义设置。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

