

Hadoop入门教程:MapReduce序列化和反序列化
Hadoop入门教程:MapReduce序列化和反序列化,序列化是指将结构化对象转为字节流以便于通过网络进行传输或写入持久存储的过程。反序列化指的是将字节流转为结构化对象的过程。在Hadoop MapReduce中,序列化的主要作用有两个:永久存储和进程间通信。
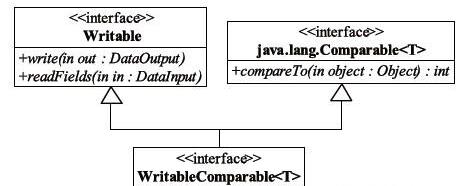
为了能够读取或者存储Java对象,MapReduce编程模型要求用户输入和输出数据中的key和value必须是可序列化的。在Hadoop MapReduce中,使一个Java对象可序列化的方法是让其对应的类实现Writable接口。但对于key而言,由于它是数据排序的关键字,因此还需要提供比较两个key对象的方法。为此,key对应类需实现WritableComparable接口,它的类如图所示。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

