

Hadoop入门教程:HDFS架构分析
Hadoop入门教程:HDFS架构分析,HDFS是一个具有高度容错性的分布式文件系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS的架构如图所示,总体上采用了master/slave架构,主要由以下几个组件组成:Client、NameNode、Secondary、NameNode和DataNode。下面分别对这几个组件进行介绍。
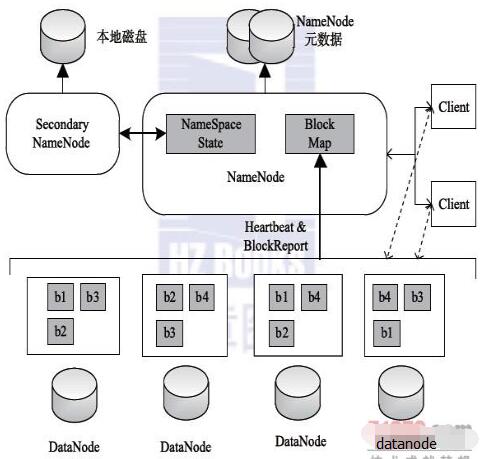
(1)Client
Client(代表用户)通过与NameNode和DataNode交互访问HDFS中的文件。Client提供了一个类似POSIX的文件系统接口供用户调用。
(2)NameNode
整个Hadoop集群中只有一个NameNode。它是整个系统的“总管”,负责管理HDFS的目录树和相关的文件元数据信息。这些信息是以“fsimage”(HDFS元数据镜像文件)和 “editlog”(HDFS文件改动日志)两个文件形式存放在本地磁盘,当HDFS重启时重新构造出来的。此外,NameNode还负责监控各个DataNode的健康状态,一旦发现某个DataNode宕掉,则将该DataNode移出HDFS并重新备份其上面的数据。
(3)Secondary NameNode
Secondary NameNode最重要的任务并不是为NameNode元数据进行热备份,而是定期合并fsimage和edits日志,并传输给NameNode。这里需要注意的是,为了减小NameNode压力,NameNode自己并不会合并fsimage和edits,并将文件存储到磁盘上,而是交由Secondary NameNode完成。
(4)DataNode
一般而言,每个Slave节点上安装一个DataNode,它负责实际的数据存储,并将数据信息定期汇报给NameNode。DataNode以固定大小的block为基本单位组织文件内容,默认情况下block大小为64MB。当用户上传一个大的文件到HDFS上时,该文件会被切分成若干个block,分别存储到不同的DataNode;同时,为了保证数据可靠,会将同一个block以流水线方式写到若干个(默认是3,该参数可配置)不同的DataNode上。这种文件切割后存储的过程是对用户透明的。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

