

Hadoop入门教程:ipc.Server类介绍
Hadoop入门教程:ipc.Server类介绍,Hadoop RPC主要由三个大类组成,ipc.RPC是其中一个,对应服务器实现,Hadoop采用了Master/Slave结构,其中Master是整个系统的单点,如NameNode或JobTracker,这是制约系统性能和可扩展性的最关键因素之一;而Master通过ipc.Server接收并处理所有Slave发送的请求,这就要求ipc.Server 将高并发和可扩展性作为设计目标。
为此,ipc.Server采用了很多提高并发处理能力的技术,主要包括线程池、事件驱动和Reactor设计模式等,这些技术均采用了JDK自带的库实现,这里重点分析它是如何利用Reactor设计模式提高整体性能的。
Reactor是并发编程中的一种基于事件驱动的设计模式,它具有以下两个特点:通过派发/分离I/O操作事件提高系统的并发性能;提供了粗粒度的并发控制,使用单线程实现,避免了复杂的同步处理。典型的Reactor实现原理如图3-8所示。
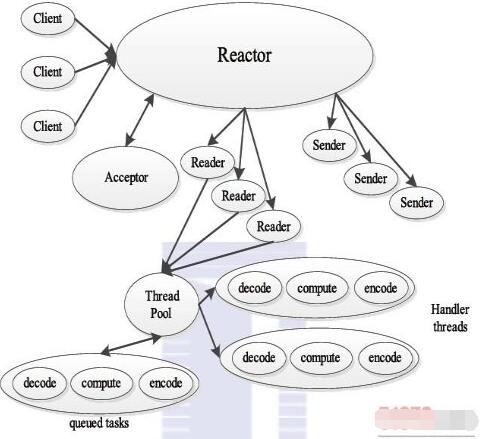
典型的Reactor模式中主要包括以下几个角色。
Reactor:I/O事件的派发者。
Acceptor:接受来自Client的连接,建立与Client对应的Handler,并向Reactor注册此Handler。
Handler:与一个Client通信的实体,并按一定的过程实现业务的处理。Handler内部往往会有更进一步的层次划分,用来抽象诸如read、decode、compute、encode和send等过程。在Reactor模式中,业务逻辑被分散的I/O事件所打破,所以Handler需要有适当的机制在所需的信息还不全(读到一半)的时候保存上下文,并在下一次I/O事件到来的时候(另一半可读)能继续上次中断的处理。
Reader/Sender:为了加速处理速度,Reactor模式往往构建一个存放数据处理线程的线程池,这样数据读出后,立即扔到线程池中等待后续处理即可。为此,Reactor模式一般分离Handler中的读和写两个过程,分别注册成单独的读事件和写事件,并由对应的Reader和Sender线程处理。
ipc.Server实际上实现了一个典型的Reactor设计模式,其整体架构与上述完全一致。一旦读者了解典型Reactor架构便可很容易地学习ipc.Server的设计思路及实现。接下来,我们分析ipc.Server的实现细节。
前面提到,ipc.Server的主要功能是接收来自客户端的RPC请求,经过调用相应的函数获取结果后,返回给对应的客户端。为此,ipc.Server被划分成3个阶段:接收请求、处理请求和返回结果。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

