

Hadoop入门教程:ipc.Client类介绍
Hadoop入门教程:ipc.Client类介绍,Hadoop RPC主要由三个大类组成,Client是其中一个,对应客户端实现,Client主要完成的功能是发送远程过程调用信息并接收执行结果。
Client类对外提供了一类执行远程调用的接口,这些接口的名称一样,仅仅是参数列表不同,比如其中一个的声明如下所示:
public Writable call(Writable param, ConnectionIdremoteId) throws InterruptedException, IOException;
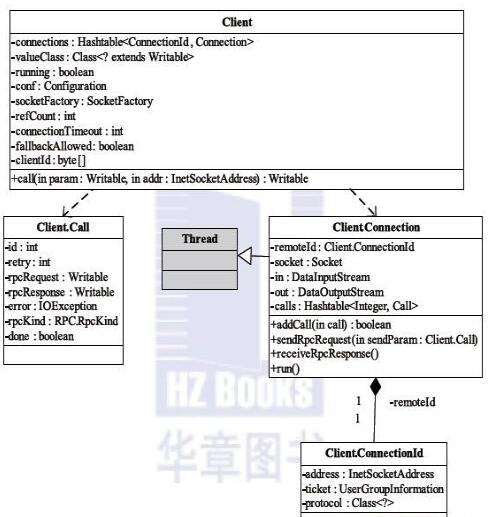
Client内部有两个重要的内部类,分别是Call和Connection。
Call类:封装了一个RPC请求,它包含5个成员变量,分别是唯一标识id、函数调用信息param、函数执行返回值value、出错或者异常信息error和执行完成标识符done。由于Hadoop RPC Server采用异步方式处理客户端请求,这使远程过程调用的发生顺序与结果返回顺序无直接关系,而Client端正是通过id识别不同的函数调用的。当客户端向服务器端发送请求时,只需填充id和param两个变量,而剩下的3个变量(value、error和done)则由服务器端根据函数执行情况填充。
Connection类:Client与每个Server之间维护一个通信连接,与该连接相关的基本信息及操作被封装到Connection类中,基本信息主要包括通信连接唯一标识(remoteId)、与Server端通信的Socket(socket)、网络输入数据流(in)、网络输出数据流(out)、保存RPC请求的哈希表(calls)等。操作则包括:
addCall—将一个Call对象添加到哈希表中;
sendParam—向服务器端发送RPC请求;
receiveResponse —从服务器端接收已经处理完成的RPC请求;
run—Connection是一个线程类,它的run方法调用了receiveResponse方法,会一直等待接收RPC返回结果。
当调用call函数执行某个远程方法时,Client端需要进行(如图3-7所示)以下4个步骤。
1)创建一个Connection对象,并将远程方法调用信息封装成Call对象,放到Connection对象中的哈希表中;
2)调用Connection类中的sendRpcRequest()方法将当前Call对象发送给Server端;
3)Server端处理完RPC请求后,将结果通过网络返回给Client端,Client端通过receiveRpcResponse()函数获取结果;
4)Client检查结果处理状态(成功还是失败),并将对应Call对象从哈希表中删除。

-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

