

Hadoop入门教程:ipc.RPC类分析
Hadoop入门教程:ipc.RPC类分析,Hadoop RPC主要由三个大类组成,ipc.RPC是其中一个,对应对外编程接口,RPC类实际上是对底层客户机–服务器网络模型的封装,以便为程序员提供一套更方便简洁的编程接口。
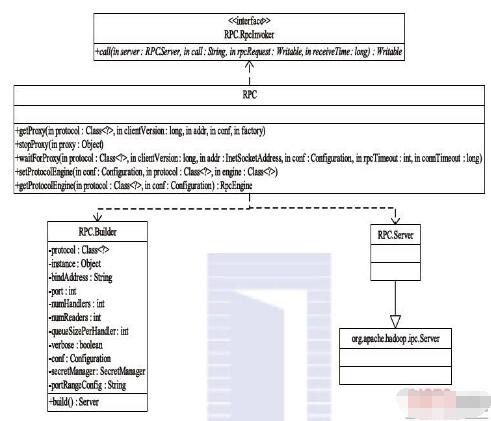
如图所示,RPC类定义了一系列构建和销毁RPC客户端的方法,构建方法分为getProxy和waitForProxy两类,销毁方只有一个,即为stopProxy。RPC服务器的构建则由静态内部类RPC.Builder,该类提供了一些列setXxx方法(Xxx为某个参数名称)供用户设置一些基本的参数,比如RPC协议、RPC协议实现对象、服务器绑定地址、端口号等,一旦设置完成这些参数后,可通过调用RPC.Builder.build()完成一个服务器对象的构建,之后直接调用Server.start()方法便可以启动该服务器。
与Hadoop 1.x中的RPC仅支持基于Writable序列化方式不同,Hadoop 2.x允许用户使用其他序列化框架,比如Protocol Buffers等,目前提供了Writable(WritableRpcEngine)和Protocol Buffers(ProtobufRpcEngine)两种,默认实现是Writable方式,用户可通过调用RPC.setProtocolEngine(…)修改采用的序列化方式。
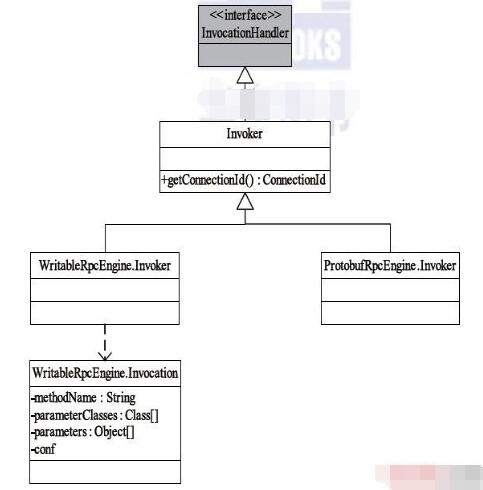
下面以采用Writable序列化为例(采用Protocol Buffers的过程类似),介绍Hadoop RPC的远程过程调用流程。Hadoop RPC使用了Java动态代理完成对远程方法的调用:用户只需实现java.lang.reflect.InvocationHandler接口,并按照自己需求实现invoke 方法即可完成动态代理类对象上的方法调用。但对于Hadoop RPC,函数调用由客户端发出,并在服务器端执行并返回,因此不能像单机程序那样直接在invoke 方法中本地调用相关函数,它的做法是,在invoke方法中,将函数调用信息(函数名,函数参数列表等)打包成可序列化的WritableRpcEngine.Invocation对象,并通过网络发送给服务器端,服务端收到该调用信息后,解析出和函数名,函数参数列表等信息,利用Java反射机制完成函数调用,期间涉及到的类关系如下图所示。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

