

Hadoop入门教程:Hadoop怎么安装配置
Hadoop入门教程:Hadoop怎么安装配置,Hadoop共有三种部署方式:本地模式,伪分布模式及集群模式。本次安装配置以伪分布模式为主,即在一台服务器上运行Hadoop(如果是分布式模式,则首先要配置Master主节点,其次配置Slave从节点)。以下说明如无特殊说明,默认使用root用户登录主节点,进行以下的一系列配置。
安装配置前请先准备好以下软件:
vmware workstation 8.0或以上版本
redhat server 6.x版本或centos 6.x版本
jdk-6u24-Linux-xxx.bin
hadoop-1.1.2.tar.gz
设置静态IP地址
命令模式下可以执行setup命令进入设置界面配置静态IP地址;x-window界面下可以右击网络图标配置;
配置完成后执行service network restart重新启动网络服务;
验证:执行命令ifconfig
修改主机名
<1>修改当前会话中的主机名(这里我的主机名设为hadoop-master),执行命令hostname hadoop-master
<2>修改配置文件中的主机名,执行命令vi /etc/sysconfig/network
验证:重启系统reboot
DNS绑定
执行命令vi /etc/hosts,增加一行内容,如下(这里我的Master节点IP设置的为192.168.80.100):
192.168.80.100 hadoop-master
保存后退出
验证:ping hadoop-master
关闭防火墙及其自动运行
<1>执行关闭防火墙命令:service iptables stop
验证:service iptables stauts
<2>执行关闭防火墙自动运行命令:chkconfig iptables off
验证:chkconfig --list | grep iptables
SSH(Secure Shell)的免密码登录
<1>执行产生密钥命令:ssh-keygen –t rsa,位于用户目录下的.ssh文件中(.ssh为隐藏文件,可以通过ls –a查看)
<2>执行产生命令:cp id_rsa.pub authorized_keys
验证:ssh localhost
复制JDK和Hadoop-1.1.2.tar.gz至Linux中
<1>使用WinScp或CuteFTP等工具将jdk和hadoop.tar.gz复制到Linux中(假设复制到了Downloads文件夹中);
<2>执行命令:rm –rf /usr/local/* 删除该文件夹下所有文件
<3>执行命令:cp /root/Downloads/* /usr/local/ 将其复制到/usr/local/文件夹中
安装JDK
<1>在/usr/local下解压jdk安装文件:./jdk-6u24-Linux-i586.bin(如果报权限不足的提示,请先为当前用户对此jdk增加执行权限:chmod u+x jdk-6u24-Linux-i586.bin)
<2>重命名解压后的jdk文件夹:mv jdk1.6.0_24 jdk(此步凑非必要,只是建议)
<3>配置Linux环境变量:vi /etc/profile,在其中增加几行:
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
<4>生效环境变量配置:source /etc/profile
验证:java –version
安装Hadoop
<1>在/usr/local下解压hadoop安装文件:tar –zvxf hadoop-1.1.2.tar.gz
<2>解压后重命名hadoop-1.1.2文件夹:mv hadoop-1.1.2 hadoop(此步凑非必要,只是建议)
<3>配置Hadoop相关环境变量:vi /etc/profile,在其中增加一行:
export HADOOP_HOME=/usr/local/hadoop
然后修改一行:
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME:$PATH
<4>生效环境变量:source /etc/profile
<5>修改Hadoop的配置文件,它们位于$HADOOP_HOME/conf目录下。
分别修改四个配置文件:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml;
具体下修改内容如下:(由于修改内容较多,建议使用WinScp进入相关目录下进行编辑和保存,可以节省较多时间和精力)
5.1【hadoop-env.sh】 修改第九行:
export JAVA_HOME=/usr/local/jdk/
如果虚拟机内存低于1G,还需要修改HADOOP_HEAPSIZE(默认为1000)的值:
export HADOOP_HEAPSIZE=100
5.2【core-site.xml】 在configuration中增加以下内容(其中的hadoop-master为你配置的主机名):
fs.default.name
hdfs://hadoop-master:9000
change your own hostname
hadoop.tmp.dir
/usr/local/hadoop/tmp
5.3 【hdfs-site.xml】 在configuration中增加以下内容:
dfs.replication
1
dfs.permissions
false
5.4 【mapred-site.xml】 在configuration中增加以下内容(其中的hadoop-master为你配置的主机名):
mapred.job.tracker
hadoop-master:9001
change your own hostname
<6>执行命令对Hadoop进行初始格式化:hadoop namenode –format
<7>执行命令启动Hadoop:start-all.sh(一次性启动所有进程)
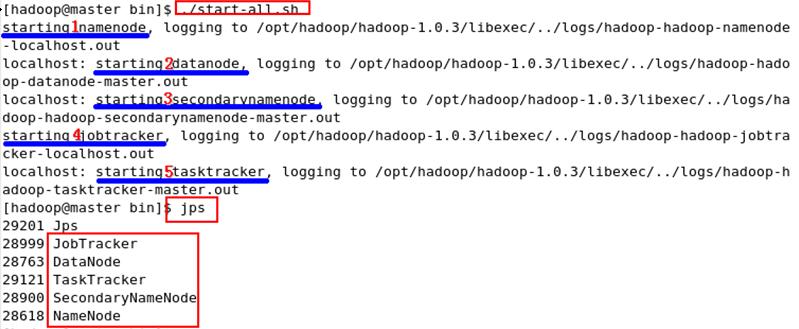
第二种方式:通过执行如下方式命令单独启动HDFS和MapReduce:start-dfs.sh和start-mapred.sh启动,stop-dfs.sh和stop-mapred.sh关闭;
第三种方式:通过执行如下方式命令分别启动各个进程:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start jobtracker
hadoop-daemon.sh start tasktracker
这种方式的执行命令是hadoop-daemon.sh start [进程名称],这种启动方式适合于单独增加、删除节点的情况,在安装集群环境的时候会看到。
验证:
① 执行jps命令查看java进程信息,如果是start-all.sh则一共显示5个java进程。
②在浏览器中浏览Hadoop,输入URL:hadoop-master:50070和hadoop-master:50030。如果想在宿主机Windows中浏览,可以直接通过ip地址加端口号访问,也可以配置C盘中System32/drivers/etc/中的hosts文件,增加DNS主机名映射,例如:192.168.80.100 hadoop-master。
访问效果如下图:
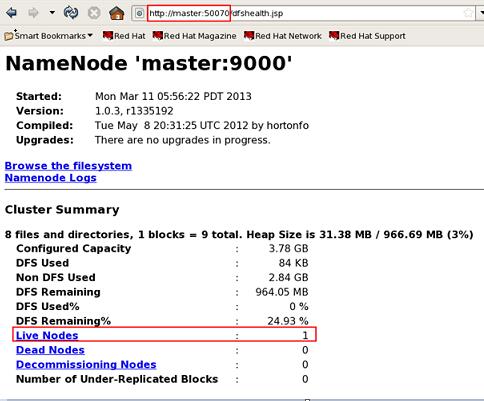
namenode
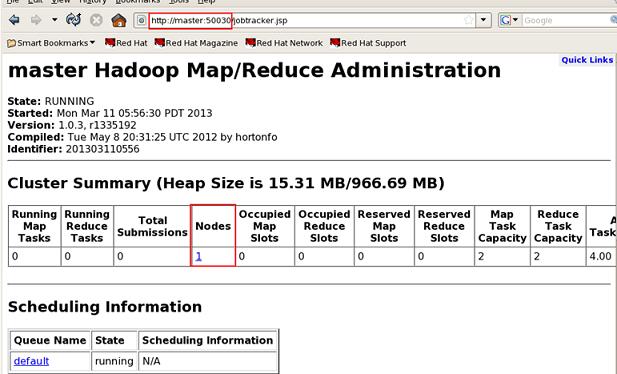
jobtracker
<8>NameNode进程没有启动成功?可以从以下几个方面检查:
没有对NameNode进行格式化操作:hadoop namenode –format(PS:多次格式化也会出错,保险操作是先删除/usr/local/hadoop/tmp文件夹再重新格式化)
Hadoop配置文件只复制没修改: 修改四个配置文件需要改的参数
DNS没有设置IP和hostname的绑定:vi /etc/hosts
SSH的免密码登录没有配置成功:重新生成rsa密钥
<9>Hadoop启动过程中出现以下警告?
【root@hadoop local】# start-all.sh
可以通过以下步凑去除该警告信息:
①首先执行命令查看shell脚本:vi start-all.sh(在bin目录下执行),可以看到如下图所示的脚本
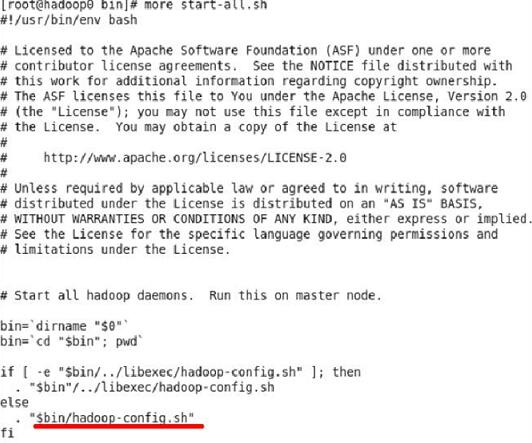
虽然我们看不懂shell脚本的语法,但是可以猜到可能和文件hadoop-config.sh有关,我们再看一下这个文件的源码。执行命令:vi hadoop-config.sh(在bin目录下执行),由于该文件特大,我们只截取最后一部分,见下图。
从图中的红色框框中可以看到,脚本判断环境变量HADOOP_HOME和HADOOP_HOME_WARN_SUPPRESS的值,如果前者为空,后者不为空,则显示警告信息“Warning??”。
我们在前面的安装过程中已经配置了HADOOP_HOME这个环境变量,因此,只需要给HADOOP_HOME_WARN_SUPPRESS配置一个值就可以了。所以,执行命令:vi /etc/profile,增加一行内容(值随便设置一个即可,这里设为0):
export HADOOP_HOME_WARN_SUPPRESS=0
保存退出后执行重新生效命令:source /etc/profile,生效后重新启动hadoop进程则不会提示警告信息了。
至此,一个Hadoop的Master节点的安装配置结束,接下来我们要进行从节点的配置。
-
标签错误:<!-- #Label#
labelId=20160707140604
moduleId=1
classId=12231768634
orderby=2
fields=url,title,u_info
attribute=
datatypeId=22192428132
recordCount=3
pageSize=
<htmlTemplate><dt><img src="/images/index_26${index}.jpg" width="100" height="62" /><a href="$url" title="${title}">${title}</a><span>${api.left(u_info,60)}</span></dt></htmlTemplate>
-->
- 我要参加技术沙龙

